そういえば、3回目の参加となるISUCONの第4回目の予選を通過してました。
結果は185チーム中、19位というなんと微妙な結果で本戦にいける事に。
事前準備
今年も@cadsと@fruweでお馴染みのメンバーで「Mr. Frank & Co: A New Hope」として登録。
前日までこんな感じの打ち合わせや予習を実地。
- 選択言語はruby
- 効率化・自動化の為にansible playbookを用意
- ssh keys
- dotfiles
- rubyの複数バージョン
- 各種ミドルウェア
- sidekiq等のバックグラウンドワーカーやキャッシュ周りの仮組み
- redisの復習
- 去年やったエントリを読む
- 当日の流れの確認
- コミュニケーションツールとして最近仕事で活躍してるSlackを導入
役割としては他の二人がコード実装に集中できるように、私がインフラ周り、コードレビュー、ファシリテーターを務める。
お題発表
不正ログイン防止の為にアクセスの失敗回数に応じてログインロックをかけるシステム。実に今風なオンラインバンキングサービス「いすこん銀行」w 最後はjsonのレポートが出力。

前半戦
まずは今までの経験からいきなりチューニングをせず、じっくりとアプリ挙動を把握し、計測し、コード解析に専念。レギュレーションもしっかり読む。この辺の衝動のコントロールはうまくなって来た感触。
アプリ自体は例年の作りによく似ていて、まあそこそこ高速化はできるだろうけど、その分他のチームも同様だろうと予想。
コードを3人で読みつつ、前日までに用意していたansibleを流したり、git化したり、計測を淡々と実地。
言語をいくつか参考値として計測した初期スコア
| language | score |
|---|---|
| ruby | 1236 |
| go | 1733 |
| perl | 1662 |
- Web側は各リスエストの比率やレスポンスタイム等を解析
- DB周りは幸いMySQLだったので全ログ出力してpt-query-digestで解析
(Postgresだったらどうしたんだろう) - OS周りはdstatやhtop等でリソースの利用具合を観測
計測やコードの理解が出来た時点で新アーキテクチャの設計を3人でディスカッションし、戦略立案。
タイムリミットをいくつか設け、いざ開始!(この時点ではまだ1行も変更してない)
基本戦略としてはMySQLのRedisへの置き換えし、アプリの処理自体を減らしていく方向。チームメイトの2人には実装を担当してもらい、その間に私が既存のMySQLバージョンのチューニングを施し、地味にスコアを上げていく。
- INDEX追加
- MySQL parameter tuning
- stylesheetsやjavascriptの直接配信
- TCP tuning
- File Descriptor上限緩和
- unix domain socketの利用
合間合間に声をかけ、実装具合や残り時間をチェックし、テンポをとる。
予め決めていた期限である14:00(ソフトリミット)に到達した時点で進捗を確認し、15:00(ハードリミット)までには間に合いそうだったのでそのまま続行を決定。
14:31にredis版が仕上がる!
実装方法
- 初期化スクリプトでMySQLからRedisへ変換
- 失敗ログインはINCRでカウント
- lockとban時にはSADDでSETに追加
- SISMEMBERでlock/banの確認
- ユーザ個別の履歴はHMSET/HMGETでハッシュ化
- /reportはSMEMBERSで出力
後半戦
Redis版のgit branchに私のコミットをマージし計測。MySQL版よりは多少良いスコア。
mysql version
tag:benchmarker type:score success:82910 fail:0 score:17910
redis version
tag:benchmarker type:score success:87810 fail:318 score:18969
CPU消費がアプリに移っていたので、後はいかにrubyに処理をさせないかの勝負となる。
ここからやったのは
- worker loadの最適値模索
- パスワードを初期化スクリプト時にオンメモリで持つように改造
- パスワードのハッシュ計算除外(ハッシュ計算のスキップは結果的にスコアには影響せず)
- トップページのエラーリダイレクトをクエリパラメータ化し、nginxで静的キャッシュ
- ログイン部分のlua実装(間に合わず)
最後のlua実装は取り掛かったものの、期限までには時間が足りないと判断し断念。かわりに失格とならないように再起動後の正常動作する事を入念に確認。
結局、ハイスコアは39243で終了
tag:benchmarker type:score success:181670 fail:0 score:39243
後で気づいたのが最高スコアではなく、最終提出スコアが最終結果となるので誤差により若干下がってしまった。。
戦いの軌跡
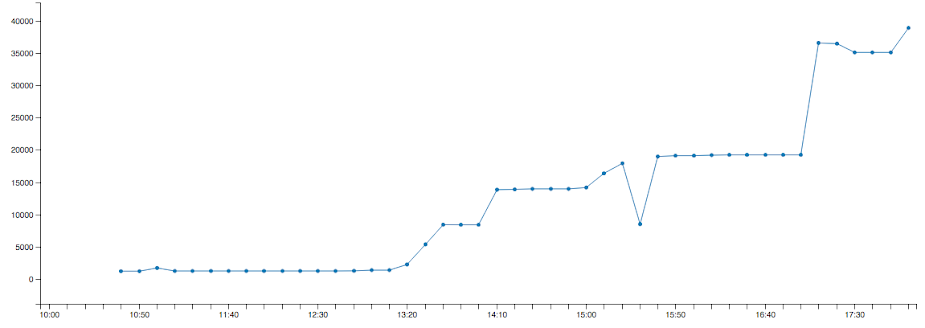
振り返り
- 戦略と遂行は概ね正しかったかと
- タイムキープ大事
- 実装は段階的に作ったので大きなバグがなかった
- ansible便利(自動化で効率化)
- Slackが非常に良かった(特にgithub連携)
- VarnishのTシャツ着てたのに使わなかった
- access_logを切るのを忘れてた!(offで試した41594だった)
- 多くのチームが失格となっていたので最終チェックは大事
- 今回は基本実装が余裕で間に合ったので確実に上達していると実感
復習
予選終了後、最後に断念したlua化を一人で実装してみた。
/login実装でスコアは5万超、/mypageまでやって6万超でした。
tag:benchmarker type:report count:banned ips value:1043
tag:benchmarker type:report count:locked users value:5290
tag:worker type:fail reason:Response code should be 201, got 403 method:POST uri:/results
tag:benchmarker type:fail message: Score sending failed reason:Response code should be 201, got 403 method:POST uri:/results
tag:benchmarker type:score success:278260 fail:0 score:60108
その後に、競技中には思いつなかったimageやcssをUser Agent判定で切って(DOM構造は変えずに)みたら15万超え
tag:benchmarker type:report count:banned ips value:3115
tag:benchmarker type:report count:locked users value:10426
tag:worker type:fail reason:Response code should be 201, got 403 method:POST uri:/results
tag:benchmarker type:fail message: Score sending failed reason:Response code should be 201, got 403 method:POST uri:/results
tag:benchmarker type:score success:210324 fail:0 score:155272
この辺が限界。
うーむ。山形組の30万超えには程遠いなぁ。恐ろしや。
最後に
運営の皆様、ベンチマークツールの不具合やインスタンスガチャの問題等ありましたが、対応方針は非常に納得のいくものでした。引き続き、本戦を楽しみにしています。ありがとうございました!

