バッチ処理等、サーバの冗長化が難しく仕方なく1台で動かさざるを得ない場合があります。でも可用性は確保したい。また、Pacemakerやkeepalived等できなくはないが、お金もあんまりかけられない場合もあります。 そんな時にAWS上でよく使うのがAutoscalingによる1台構成です。最低台数・最大台数共に「1」に設定しておけばEC2インスタンスが壊れても自動的に新しいのにリプレースされて復旧されます。
しかし、Autoscalingのhealth-check-typeを「EC2」にした場合、インスタンスの起動状態(running, stopped)しか見てくれないので、今までこの構成を実現するのにELBによる死活監視が必要でした。インスタンスがHTTPサーバじゃない場合、ちょっとムダです。
ところが、ちょっと前にAutoscalingがインスタンスの健康状態をチェックするEC2 status checkに対応し、ELBが不要になったはずなので試してみました。
今回は各種AWSサービスに対応した統合されたPython版のAWS CLIツールを使います。
セットアップ
まずは、ツールのインストール
sudo apt-get install python-pip
sudo pip install awscli
complete -C aws_completer aws
Autoscaling設定
Launch Configの設定
aws autoscaling create-launch-configuration --image-id ami-4a12aa4b \
--launch-configuration-name test-lc --instance-type t1.micro --key-name ijin-tokyo \
--security-groups test --iam-instance-profile test_iam
{
"ResponseMetadata": {
"RequestId": "c0e66974-7103-11e2-9780-a53199bac60e"
}
}
Scaling Groupの設定
aws autoscaling create-auto-scaling-group --auto-scaling-group-name test-sg \
--launch-configuration-name test-lc --min-size 1 --max-size 1 \
--health-check-grace-period 180 --tags '{"key":"Name", "value":"as-test"}' \
'{"key":"Use Case", "value":"test"}' --availability-zones ap-northeast-1a --health-check-type "EC2"
{
"ResponseMetadata": {
"RequestId": "e3808ef3-7103-11e2-9780-a53199bac60e"
}
}
通知
aws autoscaling put-notification-configuration --auto-scaling-group-name test-sg \
--topic-arn arn:aws:sns:ap-northeast-1:521026608000:test \
--notification-types autoscaling:EC2_INSTANCE_LAUNCH autoscaling:EC2_INSTANCE_TERMINATE \
autoscaling:EC2_INSTANCE_LAUNCH_ERROR autoscaling:EC2_INSTANCE_TERMINATE_ERROR
{
"ResponseMetadata": {
"RequestId": "f68359be-7103-11e2-9a1a-5f77b12b596e"
}
}
レスポンスがjsonなのが良いですね。 また、Auto Scaling Command Line Toolと違って、tagでスペースが使えるようになったのが素晴らしい!
以上の設定でAutoscalingによってインスタンスが1台立ち上がります。
自動復旧
最後にインスタンス不調(status check failure)をシミュレートする為にインスタンス内からネットワークを落とします。
ubuntu@ip-10-128-25-25:~$ sudo ifdown eth0
これでstatus checkがfailし、Autoscalingが自動的に新しいインスタンスと取り替えてくれるはず!
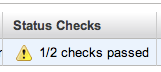

と、期待して待っていたらなかなかアラートメールが来ません。。
設定間違ったかなーっていろいろ見直していたら20分経った頃にやっと到着。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
うーん。動く事は動いたけど、ちょっと時間がかかるなぁ。
この後何回か試してみたけど、Autoscaling発動までどれも20分ぐらいかかりました。
結論
20分程サーバダウンが許容できるようなゆるめの条件に限定した場合には非ELBでも使えるかな。まあ、それでも適用する場面は多々あるとは思いますが。(早める方法あるのかなー。)