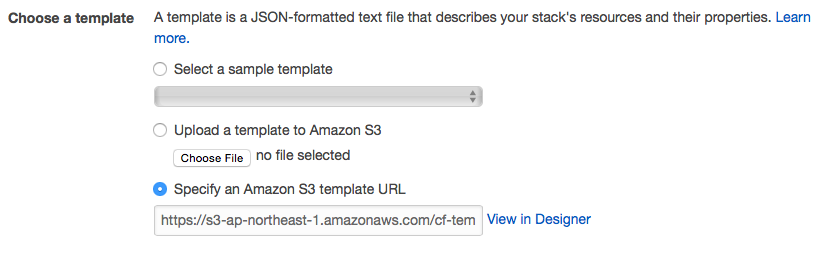
つい先日、Terraformでずっと気になっていたAmazon API Gatewayのselection_patternのpull requestがmergeされました。
今まではAPI GWをInfrastructure As Codeで構築するにあたって複数のintegration responseパターンを返却できないのがネックだったのが、これでようやく解決。途中までTerraformで作って、その後に以下のようにawscliで追加するというちょっと煩わしい手順でした。
リソースを作成するのに並列処理が出来なかったり、依存関係がまだうまく対応できてないので、depends_onを駆使する必要があるのが若干まだ面倒。ない場合は、BadRequestException: Unable to complete operation due to concurrent modification. Please try again laterやBadRequestException: No integration defined for method status code: 400等のエラーが発生する。
API Gatewayはresource, method, integration, method response、integration response等を記述しないといけないので、どうしてもコードが多くになってしまう事からSwaggerでやった方が楽だったりするかも。ただ、その場合はInfrastructure as YAMLになってしまうけど。。また、YAMLは整形してからimportする必要があったりするので、その辺は諸々トレードオフかなぁ。
sed -i -e "s/dev/dev - `git rev-parse --short HEAD`/" terraform/version.go
ビルド
make devすると全pluginやproviderがコンパイルされ、非常に時間がかかる(特に最近は対応範囲の広がりが著しく、生成されるバイナリの総容量が増加傾向)。
よって、特定のproviderを指定して時間短縮する。以下はaws providerで作業している場合。
1234567
$ make core-dev plugin-dev PLUGIN=provider-aws
==> Checking that code complies with gofmt requirements...
/Users/ijin/golang/bin/stringer
go generate $(go list ./... | grep -v /vendor/)
go install github.com/hashicorp/terraform
go install github.com/hashicorp/terraform/builtin/bins/provider-aws
mv /Users/ijin/golang/bin/provider-aws /Users/ijin/golang/bin/terraform-provider-aws
確認
12
$ terraform version
Terraform v0.6.15-dev - 123abcd
$ ./aws-api-import.sh -c swagger.json
2015-11-04 02:23:18,507 INFO - Attempting to create API from Swagger definition. Swagger file: swagger.json
reading from swagger.json
2015-11-04 02:23:18,649 INFO - Parsed Swagger with 2 paths
2015-11-04 02:23:18,655 INFO - Creating API with name EB API
2015-11-04 02:23:19,417 INFO - Removing default model Error
2015-11-04 02:23:19,634 INFO - Removing default model Empty
2015-11-04 02:23:19,872 INFO - Creating model for api id nx3r6d6yhh with name IP
2015-11-04 02:23:20,114 INFO - Generated json-schema for model IP: {"type":"object","properties":{"ip":{"type":"string","description":"IP address."}},"definitions":{}}
2015-11-04 02:23:20,329 INFO - Creating model for api id nx3r6d6yhh with name Error
2015-11-04 02:23:20,338 INFO - Generated json-schema for model Error: {"type":"object","properties":{"code":{"type":"integer","format":"int32"},"message":{"type":"string"},"fields":{"type":"string"}},"definitions":{}}
2015-11-04 02:23:20,770 INFO - Creating resource 'eb' on bd5pqsq37h
2015-11-04 02:23:21,420 INFO - Creating resource '{env_name}' on 8rjsbt
2015-11-04 02:23:22,079 INFO - Creating resource 'ip' on 4cg26s
2015-11-04 02:23:22,931 INFO - Creating method response for api nx3r6d6yhh and method GET and status 200
2015-11-04 02:23:23,144 INFO - Creating new model referenced from response: IPaddresses
2015-11-04 02:23:23,144 INFO - Creating model for api id nx3r6d6yhh with name IPaddresses
2015-11-04 02:23:23,153 INFO - Generated json-schema for model IPaddresses: {"type":"string","definitions":{}}
2015-11-04 02:23:23,770 WARN - Default response not supported, skipping
2015-11-04 02:23:23,772 INFO - Creating method parameter for api nx3r6d6yhh and method GET with name method.request.path.env_name
2015-11-04 02:23:23,998 INFO - Creating method for api id nx3r6d6yhh and resource id md6qcm with method get
2015-11-04 02:23:24,822 INFO - Creating resource '{server_num}' on qmd6mc
2015-11-04 02:23:25,689 INFO - Creating method response for api nx3r6d6yhh and method GET and status 200
2015-11-04 02:23:25,896 INFO - Found reference to existing model IPaddresses
2015-11-04 02:23:26,306 WARN - Default response not supported, skipping
2015-11-04 02:23:26,306 INFO - Creating method parameter for api nx3r6d6yhh and method GET with name method.request.path.env_name
2015-11-04 02:23:26,525 INFO - Creating method parameter for api nx3r6d6yhh and method GET with name method.request.path.server_number
2015-11-04 02:23:26,764 INFO - Creating method for api id nx3r6d6yhh and resource id 5udxeo with method get